As a reminder, we started with a description of what's needed right at the beginning of the data chain in order to make the whole ecosystem viable - i.e. CAPTURE the data and have a means of addressing devices.
After capturing the data, we examined the architectures available to shift and store the captured data and how to CURATE it.
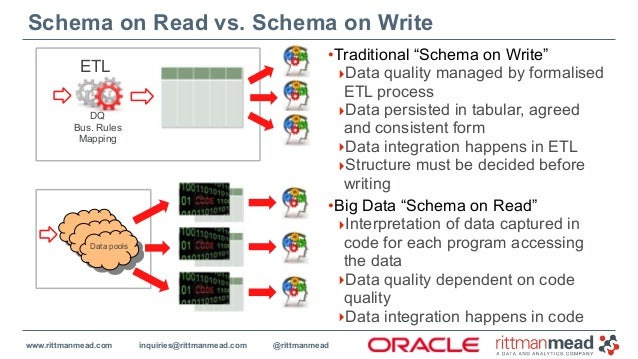
Now that we have the data, what do we do next to turn it into actionable information? Well, we need a way of applying business rules, logic, statistics, maths "& stuff", i.e. the CALCULATE layer.
Statistical Modelling
Once the domain of products such as SAS and IBM's SPSS, this approach takes traditional statistical techniques to, among other things, determine correlation between data points and establish linkages using parameters, constants and variables to model real world events.
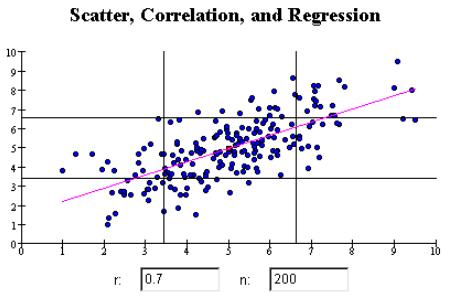
The new kid on the street is "R", an Open Source programming language which provides access to many statistical libraries. Such is the success of this initiative that many vendors now integrate with R in order to extend their own capabilities.
Machine Learning
Whereas with Statistical Modelling, which starts with a hypothesis upon which statistics are used to verify, validate and then model the hypothesis, Machine Learning starts with the data....and it's the computer that establishes the hypothesis. It then builds a model and then iterates, consuming additional data to validate its own models.

This is rather than Data Mining at Hyperspeed. It allows data to be consumed, and models created, from which no prior (domain specific) knowledge is required. A good demonstration of this can be seen on the aiseedo.com cookie monster demonstration.
Cognitive Computing
This brings together machine learning and natural language processing in order to automate the analysis of unstructured data (particularly written and spoken data). As such, it crosses the boundaries between the computation and the analysis layers of the Mega Data stack. Further details have been published on the Silicon Angle website.
Algorithms
Algorithms are the next step on from statistical modelling. Statistics identify trends/correlations and probabilities. Algorithms are used to provide recommendations and are deployed extensively in electronic trading. This architecture of a Trading Floor from Cisco illustrates their use:
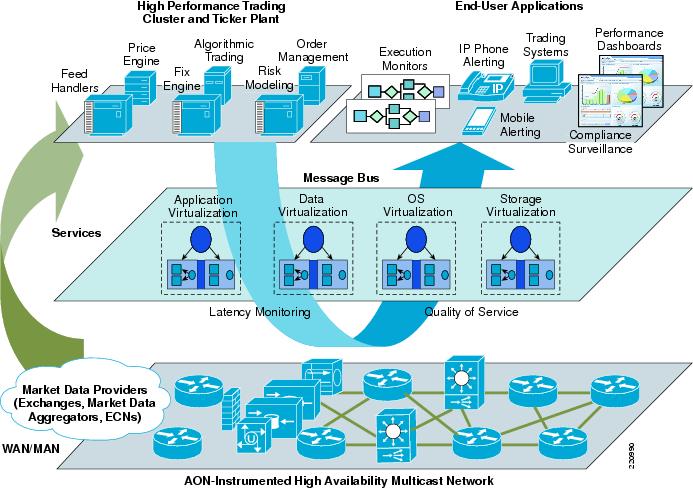
As can be seen from the above, algorithmic trading takes data from many other sources, including price and risk modelling, and is then used to deliver an automated trading platform.
Deep Analytics
Probably the best known example of this genre is IBM's Watson. This technology was developed to find answers in unstructured data. Its first (public) application was to participate in the US TV show Jeopardy!.

The novel feature about the TV show was that, unlike typical quiz shows where contestants are asked to answer questions, the competitors are given the answer and need to identify what the question is. This provided an usual computing challenge against which the developers of IBM's Watson succeeded when the system competed against two of the show's previous winners and won in February 2011.
Cloud Compute
So far the other elements described in this blog are about the maths. How you provide the compute capability is where Cloud Compute fits nicely.
If you have unlimited funding available, then a typical architecture to run your compute needs is on a supercomputer. These are, however, incredibly expensive, and are the remit of government sponsored organisations. The current "top of the range" supercomputer is the Chinese Defence Tiahne-2,

With over three million CPU cores, it featured as the number 1 supercomputer in the World in November 2014.
An alternative means of harnessing power is to use Grid Computing, which links many computers together:

This brings an advantage that compute power can be added as needed.If you have unlimited funding available, then a typical architecture to run your compute needs is on a supercomputer. These are, however, incredibly expensive, and are the remit of government sponsored organisations. The current "top of the range" supercomputer is the Chinese Defence Tiahne-2,

With over three million CPU cores, it featured as the number 1 supercomputer in the World in November 2014.
An alternative means of harnessing power is to use Grid Computing, which links many computers together:

Finally, Cloud Compute provides the most flexible means of accessing compute power as the consumer of the compute doesn't normally need to procure/provision the hardware themselves. This means that compute is available using a per use pricing model.
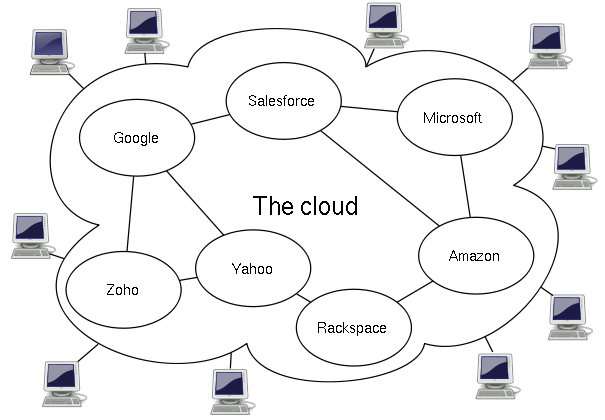
This typically provides access to extensible compute power without the upfront procurement costs and so makes it incredibly flexible and cost effective.
Hopefully this snapshot of compute architectures provides a useful starting point from which we'll examine in greater detail how such capabilities can be exploited.
A reminder finally that we have a Meetup Group which provides the opportunity to meet like minded people and to hear from others about the Mega Data Ecosystem.
Check out these additional resources:
Meetup Mashup Group
Meetup Mashup LinkedIn Group
Facebook Page
Google+ Community