Firstly, it's worth explaining why use the word "Curate", as opposed to "collect", "contain" or "compile". If we look at Wikipedia's definition of the term Digital Curation:

We can see that curate covers so much more than simply extracting and storing digital assets. As data volumes continue to grow, we will see a transition from traditional extract and storage methods to more scalable and flexible solutions.

Whilst there are variation on this architecture, the principle is remains that data is taken from source systems, "tranformed" (e.g. aggregated, converted, made consistent, conformed, mapped t reference data), and then loaded into a database using a denormalised format. Whilst database purists often balk at the theoretical inefficiency of denormalising data (as it leads to significant duplication of data) it actually provides a faster means for the data to then be analysed and reported on. The main ETL variation,touted by some vendors is Extract-Load-Transform (ELT). In this case the data is loaded into the central repository before transformation rules are applied.
So, what will future data curation architectures look like? This depends upon which vendor you ask! Main contenders include terms such as Data Federation, Data Virtualisation, Schema on Readand Data Lakes. The latter being a term that sends shivers down the spine when one wonders.....whilst you'd be willing to put your physical assets into a warehouse, would you willingly tip them into a lake?
Data Federation is nicely described by SAS with this diagram:

In comparison, Information Management illustrates Data Virtualisation as:

So, not really much difference. In both cases source data is segregated from the presentation layer and the source data remains in the original location, i.e. it's no longer physically copied to a single central repository.
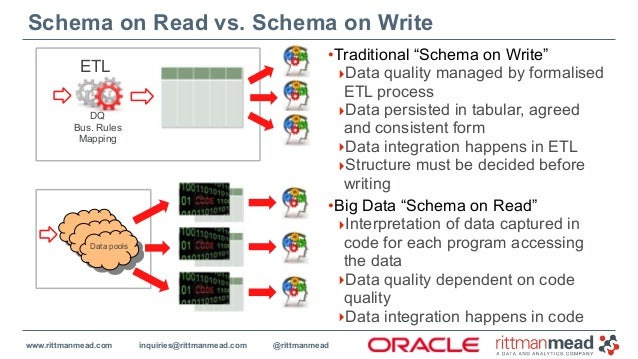
The interesting development is with Schema on Read vs Schema on Write. The qucikest way to learn more about this is to check out the presentation given at an Oracle User Group event in 2014:
So, what about Data Lakes? Pivotal's Point of View Blog give a nice description:

Which doesn't look that different to the original ETL that this post started with!
As data volumes grow and speed of data generation continues to increase there will be challenges to overcome and the above architectures are moving in the right direction. The above approaches encapsulate the solution space from a database and software perspective, so it's worth finally looking at what the hardware world is looking at. IBM, amongst others no doubt, has realised that the real problem is that the ultimate constraint is what lies between the point of collection and the point of calculation. To quote a recent speaker at a BCS Lecture "the speed of light just isn't fast enough any more". The hardware solution seems to be to move the data as close to the calculate layer as possible. We'll look at that as part of the next episode of this blog!
No comments:
Post a Comment